Cohesity and Veritas have joined forces!
See why this is a game changer for the data security space.





データサイロとは、組織内の異なるシステムに保存されたデータを含む、隔離されたリポジトリのことです。通常は他のデータストアとは異なる互換性のない形式でスタンドアロンシステムに保存されており、所有しているグループ外の他の部門、事業単位、ユーザーから簡単にアクセスすることはできません。データサイロは組織のメンバーによって定期的に使用されている場合もあれば、チームに必要とされなくなってアイドル状態になっている場合もあり、ランサムウェア攻撃に対してより脆弱になります。
データサイロは、異なる部門や事業単位が独立して動き、それぞれが独自のミッション、目標、IT予算までもを所有する場合に生じます。例えば、人事部には通常、そのニーズに合わせて最適化された独自の従業員データベースがありますが、これは企業の他の部門とは共有されていません。
データサイロが生じる主な理由は次の通りです:
組織の各部門にはそれぞれ独自のニーズがあるため、独立して活動します。そのため、特定のニーズには対応しているものの、ビジネスの他の部分とは一致しないカスタマイズされた製品やポイント製品が最終的に作成されることになります。そうすると分散化されて個別に管理され、簡単に統合できなくなります。
ポリシーやベストプラクティスなどの明確なデータガバナンス戦略がなければ、組織全体でのデータの管理や共有プロセスが標準化されなくなります。その結果、データサイロが急増します。
古くて時代遅れのテクノロジーは、最新のデータ管理ソリューションと互換性がない可能性があります。その結果、システムに最新のサイバー脅威に対するパッチが適用されなかったり、データが隔離されたりして分析に使用できず、再収益化や復旧が容易にできなくなります。
さまざまな部門には異なるニーズがありますが、異なるシステムを使用することで、相互運用性がない、または他のシステムとシームレスにデータを共有できない可能性があるため、データサイロを引き起こす可能性があります。
他の企業の買収や合併を行う組織では、すべてのデータストアが適切に変換または統合されるまで、ほぼ確実にデータサイロが発生します。明らかなデータサイロに加えて、新たに統合された組織で特定しなければならない隠れたデータサイロの存在に注意することが重要です。
データサイロは隔離されていて所属しているグループの外からはアクセスできないため、見つけにくいことがあります。以下に、組織にデータサイロがあるサインをいくつかご紹介します:

サイロ化したデータは、データストレージや管理にかかる費用や更新費の増加など、財務に悪影響を及ぼす可能性があります。これらは、ビジネスがデータサイロから予測できる最も具体的なコストです。しかし、データサイロには以下のようなさまざまな隠れたコストも存在します:
ユーザーがサイロ化したデータに直面すると、多くの場合、メンテナンスしにくくデータの品質を損ないかねない複雑な回避策を見つけざるを得なくなります。こうなると、ビジネスプロセスや生産性が時間と共に延々と低下し続けるループに陥ります。
ビジネスの内外どちらについても、問題のあるプロセスや生産性の低下について状況を包括的に確認できる透明性がない場合、組織は収益の増加やコスト削減といった潜在的に利益を上げる機会を失う可能性があります。
ランサムウェアへの支払いやコストの高いランサムウェアからの復旧にかかる時間とコストが、データサイロの予期せぬ金銭的負担となる可能性もあります。切断されたシステムや「シャドウIT」として運用されているシステムがあると、サイバー犯罪者が侵害や悪用に成功しやすくなることがあります。
販売管理時点 (POS) システム、モバイルアプリ、SaaSのCRMシステムなど、複数のデータサイロで顧客プロファイルや取引に関する情報が断片化されていると、顧客コストが上がることもあります。ビジネスは、顧客価値を最大化するために体験やスペシャルオファーのパーソナライズを実現する、情報に富んだ顧客ビューが得られません。
デジタル時代で競争力を維持しようとする組織にとって、データサイロを排除することは非常に重要です。データサイロを排除するメリットとして、以下のものが挙げられます:
サイロがなければ、ビジネスが収集、保管したすべてのデータにアクセスすることができるため、リーダー陣はこれまで見えなかった傾向を特定し、よりスマートで迅速な意思決定が行えます。組織は新たなチャンスを捉えてパフォーマンスを細かく監視できるため、リーダー陣は利益を迅速に改善し、改善すべき領域をリアルタイムで特定することができます。
データサイロを解消して組織全体でデータを統合すると、異なる部門のユーザー間のコミュニケーションとコラボレーションも向上します。これによりユーザー間の相乗効果を見つけやすくなり、ビジネス全体の利益のために連携しやすくなります。
データサイロを解消すると、部門を横断した情報の迅速なアクセスが実現するため、組織のアジリティと競争優位性が高まります。このようなオープンなデータフローによって意思決定とコラボレーションが加速し、チームは市場の変化や顧客のニーズに合わせて迅速に対応できるようになります。組織は、データの冗長性を下げて精度を上げることで、自社の競争力を強化する、より情報に基づいたタイムリーな判断を下せるようになります。
データサイロを排除すると、ユーザーは自分の業務に必要なすべてのデータにアクセスできるようになります。また、追加のIT管理や別のデータサイロのメンテナンスが不要になるため、組織の効率が上がりコストが削減されます。
組織はサイロを排除することで、顧客からの信頼とロイヤルティを高めながら、製品のパーソナライズや質問への迅速で正確な回答を行い、カスタマーサービスの品質やエンゲージメントを向上させることができます。
データサイロを排除すると、サイバー犯罪者やランサムウェア攻撃に対するサイバーセキュリティのレジリエンスも高まります。これにより組織はより正確にリスクを評価し、コンプライアンスを維持して、評判や金銭面での損害を回避することができます。
データサイロを排除するため、組織はさまざまな対応策を講じる必要があります。これには、技術的でプロセスに基づいた、組織的な戦略が含まれます。

組織の文化によってデータサイロが生じている場合、当然その文化を変えればデータサイロを排除できます。文化を変えることは難しいので、これは容易ではありません。成功の鍵となるのは、データサイロの削除を具体的なデータ戦略の開発やデータガバナンスの取り組みに結び付けることです。このためにはコミュニケーションが重要です。コラボレーションや他者 (他の部門の人も含む) とのリソース共有について広め、早期の成功を収めてリーダー陣が組織全体での文化変革を推進するために活用できるようにします。
データサイロを解消する最良の手段は、異なるソースのデータ (およびそのデータで実施する分析) を保存し、セキュリティやコンプライアンスを考慮した上でユーザーに適切なアクセスを付与できるクラウドベースのデータリポジトリに、すべてのデータを集約することです。
データストアの統合は、データサイロを解消する最も一般的な方法です。例えば、ETL (抽出、変換、ロード) ツールはデータをソースから抽出して集約し、別のシステムに書き出します。ETLツールの一種であるELT (抽出、ロード、変換) は、より複雑で構造化されていないデータに適しています。SQLやPythonでスクリプトを記述してもデータサイロの統合は行えますが、時間がかかるため結果的にコストが増加します。
データがクラウドに一元化されて保存されている場合、IT管理者なしにデータにアクセスして分析するためのセルフサービスツールをユーザーに提供できます。これは、新たなデータサイロの発生防止や、データ駆動型のビジネスの実現に大いに役立ちます。
強力なデータセキュリティとデータ管理戦略は、既存のサイロを解消すると同時に、新たなサイロの発生を防ぐのに役立ちます。エンタープライズデータ戦略は、ビジネスのニーズやサイバーセキュリティのベストプラクティスにデータを合わせながら、標準化された実証済みのデータポリシーやプロセスを確立します。
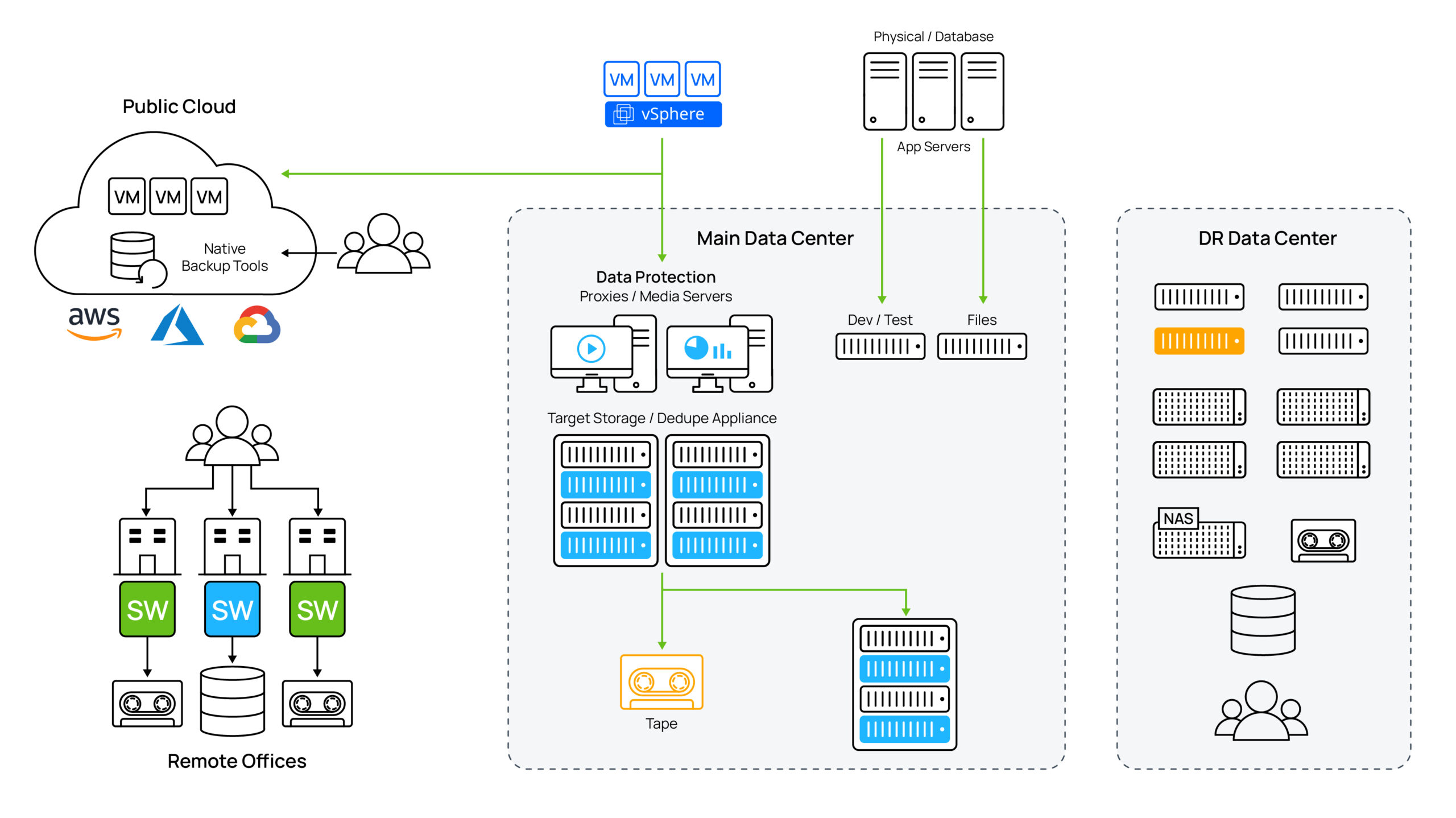
データサイロは今日の組織が直面している大きな問題の一部であり、大規模に断片化されたデータのことです。多数のロケーション、インフラストラクチャプラットフォーム、毎日使うわけではない管理システムに拡散し増加したデータが組織のデータの大部分を占めており、多くの場合、コンプライアンス要件を満たすために一定期間保管する必要があります。
データサイロをまだ解消していないチームは、貴重なデータをすべて活用することができません。完全なデジタルトランスフォーメーションができず、目標達成のためにハイブリッドクラウドやマルチクラウド環境に移行することもできません。
断片化されたデータ (「ダークデータ」としても知られます) が環境全体に散在している場合、企業はすべてのデータの場所を把握できないことはおろか、データが構造なのか非構造なのか、オブジェクトなのかファイルなのかといったことまでわからなくなります。こうしたサイロ化したデータは運用に苦労する上、コンプライアンスやセキュリティの重大なリスクとなる可能性があります。
データの大規模な断片化を引き起こす3つの主な要因は以下の通りです:
Cohesityでは、組織は以下の方法で速やかに事業目標を達成することができます:
Cohesityの実績あるアプローチは、データサイロを排除しながら、オンプレミスやSaaSソリューションを通じてインフラストラクチャを大幅にシンプル化します。Cohesityを使用すると、組織はCAPEXやOPEXを大幅に改善し、競争上の優位を得るためにすべてのデータを利用することができます。
Cohesityの製品デモの確認やエキスパートとの相談に関するご連絡は、こちらをクリックしてください。




