




Starting the journey.
Building storage at-scale is hard… and testing it can be even harder! There are a lot of things that you’ve got to consider before trekking up the mountain of scalability testing: begging sales to let me steal eight Cohesity Blocks from their upcoming manufacturing order to perform the testing; finding a place for the solution to actually live; getting together all the ancillary infrastructure components… switches, hosts, cables, etc; and finally finding the right software to actually benchmark and test it. Being no novice to early-stage startup scalability testing from my days at Nutanix, I was the lucky guy who was chosen to get these benchmarks done. This has been an incredibly rewarding experience, and I was pleasantly surprised by quite a few things throughout the process.
We reached out to analyst firm, ESG Lab, to work on a first-of-its-kind scale-out test for our Data Platform. Even though we have just announced the General Availability of our first product, ESG was up for the challenge! Our initial goal was to build out a 32-Node Cohesity Cluster and try to drive enough I/O to the Cluster through various workload scenarios. We wanted to look at random read & write performance, as well as sequential reads & writes. Each of these performance tests were also measured along with storage efficiency features enabled, such as comparing workloads with in-line data deduplication versus those without deduplication. With a rough sketch of our initial test plan in place, we started to get together the necessary hardware to prepare for testing.
With our current POC pool of resources deployed, I worked with manufacturing to get together the eight Cohesity Blocks. This was a great test for the manufacturing workflows we had put in place! It worked so well that it even beat the initial delivery target we had set, arriving before we had fully taken up space in our new co-location facility.
The testing begins.
As part of our normal in-house nightly build testing of the Cohesity Data Platform, we execute developed benchmark tests that leverage open source tools like fio and disk_bench. These are both industry standard and very robust. We generally would only test against four- or eight-Node Clusters… until I walked up to the QA team and asked if our harness would work against 32 Nodes just as easily as it did for eight. Once everyone realized I wasn’t joking, all the heads began to nod concurrently… and the gauntlet was thrown down!
The first few rounds of tests were largely unsuccessful, but not because the Cohesity Clusters couldn’t handle the load. This was because the test harness had never been tested with this many Nodes in mind. It was more of a side project to perform regression and performance testing on nightly builds and on non-production class hardware. This is where working with world-class engineers comes in handy.
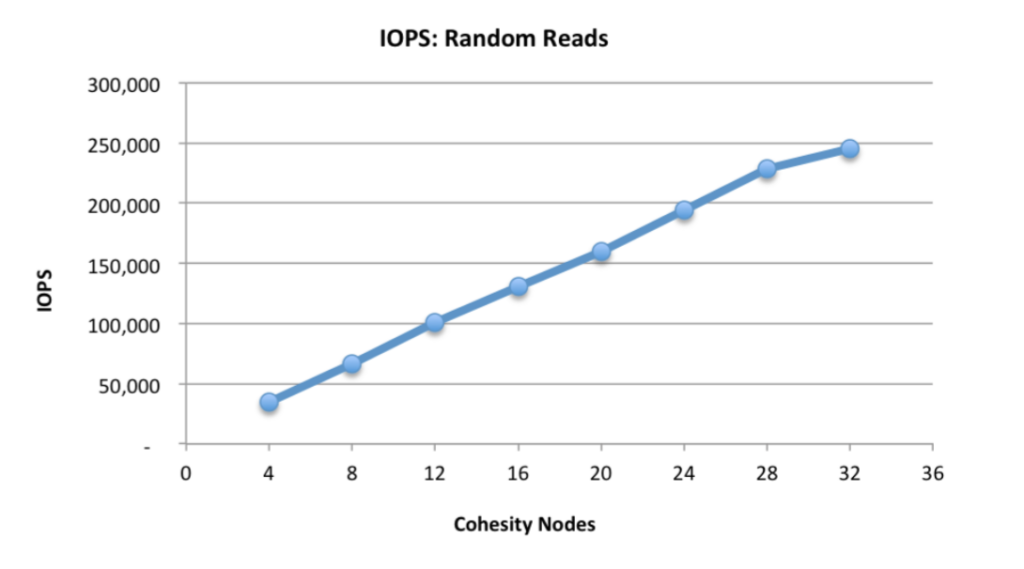
Around 3 or 4 AM of the second day of testing, our engineers had built a custom test harness that could withstand the scale of all 32 Nodes (and even beyond that), and would also drive enough I/O to saturate the Cluster. The beautiful thing about spending the up-front engineering time to build the foundations of the system right the first time is that all the numbers we generated were perfectly linear. As you can see from one of the performance graphs from the ESG Lab Spotlight Report, all workloads scaled exactly as designed as we added more Nodes to the Cluster… linearly!
In all my previous experiences performing scalability testing, I had the hardest time ensuring that the product I was testing wouldn’t fall over with the slightest breeze. But this time was much different! All the work leading up to the test was by far the hardest part in this instance… But once the testing began, the Cohesity Data Platform just worked! It just goes to show that no matter what you build, building at scale is very, very hard… but it’s well worth it when it’s done right.










