




Cost is always a factor in deploying and managing scale-out NAS. Recent health and economic events have made cost efficiencies more important than ever. Data reduction technology is an easy and straightforward way to reduce costs, but only if specific principles are observed.
Data Reduction Claims
One of the most oversold product claims presented to customers by NAS storage vendors are absolute data reduction ratios. Promises and guarantees of a 2:1 data reduction ratio… or 3:1… or 8:1 are often offered to catch the attention of an IT administrator looking to optimize spend. The truth of the matter is that data reduction efficiency is highly workload dependent. No one knows the expected data reduction ratio for your production workload until it is measured. Can a weight-loss specialist accurately forecast your weight loss without understanding your current diet and exercise routine?
Why It’s a Big Deal
The data reduction idea is simple—squeeze as much data as possible into physical storage so that you don’t have to buy more physical storage. Data reduction is a common feature of scale-out NAS because—let’s face it—who wants to buy more disks or flash than necessary?
The biggest question is how to best achieve efficient data reduction. Using an American expression, it’s efficient if you can squeeze ten pounds of potatoes into a five-pound bag. In IT speak, you aim to squeeze 100TB of source data into 50TB of target disk, or even 5 or 10TB of disk space. It’s important because superior capacity efficiency is the gift that keeps on giving, including:
- Less physical storage cost
- Lower data center footprint
- Less energy consumption
- Fewer storage devices to manage and place under a support contract
The Four Immutable Laws
From our viewpoint, there are four prerequisites to achieving leading capacity efficiency and low cost within enterprise unstructured data environments. Let’s call them “immutable laws” as it is not possible to achieve maximum data reduction across a variety of workloads for NAS products when the laws are not observed.
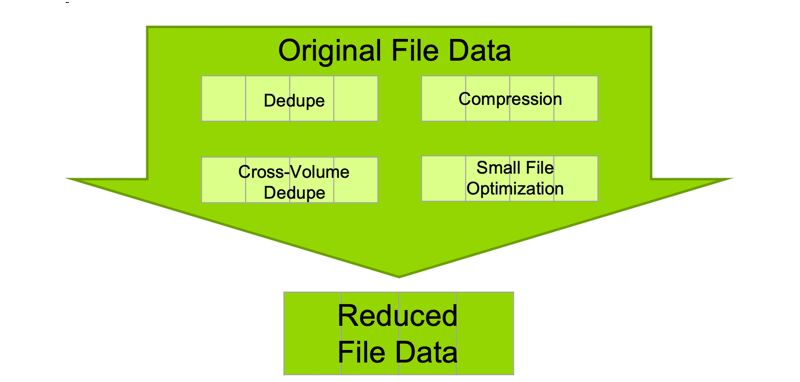
Law No. 1: Data Deduplication
This is the process of removing duplicate file data and representing the removed information (whether at file or block level) with a pointer. Although generic dedupe technology is relatively common in scale-out NAS products, not all dedupe techniques are equally efficient. For example, consider the case where two 10MB files are 90 percent the same. The most efficient deduplication technology would reduce this 20MB total down to 11MB of unique data.
File-level dedupe will keep a full-copy of each file because they are not 100 percent identical. The two 10MB files are stored at 20MB – therefore no space savings. Traditional block-level dedupe technology will dedupe within a range, depending on where the deltas exist. On average this may be 15MB (for example) for the two files assuming partial dedupe—a 25 percent space savings. That’s not bad, and most NAS products will settle for this.
The best dedupe technology adjusts the size of the blocks being stored (variable-length sliding window) such that the overall storage consumed could be 11MB for the two files—up to a 45 percent space savings and maximal efficiency. Unless a buyer asks about dedupe methodology, they may not know if data is being deduped in the most efficient way possible. Depending on the dedupe technology used, the total capacity consumed can be anywhere from 11MB to 20MB for the same files.
Yes, it is important to know how your data is being deduped.
Law No. 2: Cross-Volume Deduplication
Efficient data deduplication within a storage volume is important, but what about file data that is spread across different volumes? You know this happens today because everyone shares data with coworkers or teams, leading to modified copies across all the storage silos in your environment. Dedupe by volume cannot dedupe identical file data that resides in different storage volumes. So, the second law of data reduction says that efficient dedupe cannot be limited to the application volume domain. Without this, three 10MB files that reside on three different data center volumes will consume 30MB. The ability to dedupe across application volumes will result in only 10MB of storage consumption for the same scenario.
Law No. 3: Data Compression
Not all scale-out NAS vendors support data compression, which can result in additional reduction of data. Although some files are not easily compressed, other files are easily compressed by 2:1, 3:1, or more. In theory, most generic compression algorithms should deliver similar efficiencies. Actual implementations, however, can trade off efficiency for performance, so two vendors using the same compression algorithm can yield notably different reduction ratios. The best implementations use modern algorithms that are both efficient and performant—thus avoiding a tradeoff.
Law No. 4: Small File Optimization
Workloads consisting primarily of small files often incur a storage amplification penalty because traditional NAS systems use a fixed block size. That leads to a significant waste of space. For example, a 1KB file in a product using 8KB blocks means you’re wasting 7KB— a 7x amplification! It’s no surprise then that 100TB of small files data can easily consume 200TB to 1.5PB or more. So, the fourth law of data reduction states that file data storage must fit efficiently in the blocks they are stored within. This means that either block sizes must vary to fit the size of the small file(s), or, multiple small files must share the same storage block or blob such that no storage capacity is wasted. As with the previous three laws, a buyer may not be aware of the storage inefficiency without asking the vendor.
Going Beyond the Laws
In addition to the four laws, there are other things that can make a big difference in the total amount of hard disk space consumed in the broader data management context. Efficient architecture is assumed in modern systems file and object architecture. Being sloppy here can negate the benefit of the stated laws. A modern efficient architecture is expected to include:
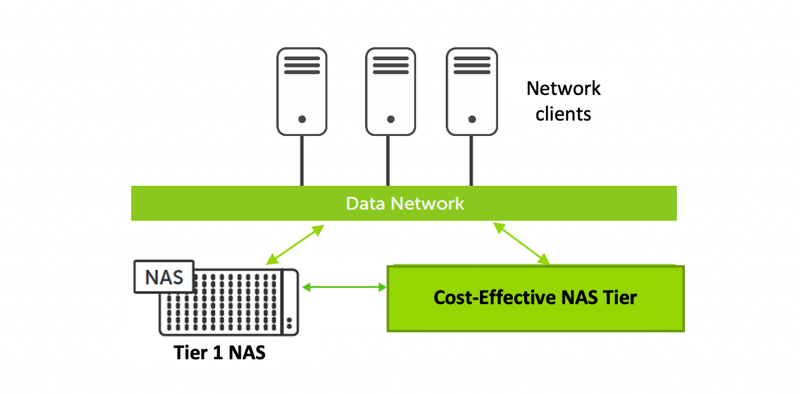
- External NAS Tiering: The ability to transparently tier colder data from costly Tier 1 NAS storage to a more cost-effective secondary NAS tier does not have to be through a third-party application. When built into secondary NAS, apps on network clients see no
 difference. Policy-driven tiering can move data to either tier. In the end, the overall cost per GB of NAS data is substantially lowered while costly Tier 1 capacity is released for apps that require Tier 1 storage or for newer data.
difference. Policy-driven tiering can move data to either tier. In the end, the overall cost per GB of NAS data is substantially lowered while costly Tier 1 capacity is released for apps that require Tier 1 storage or for newer data. - Efficient copy data management: This eliminates the capacity impact of creating extra copies. Writable snapshots (or clones) can make a huge impact in reducing storage capacity when copies are used for various purposes – including dev/test.
- Efficient replication and archiving: Making routine copies from a primary site to a secondary site is far more efficient when only the changed blocks of files are sent. Resulting file data is stored more efficiently and network bandwidth is conserved.
- Modern key-value stores for metadata and inode information: Files of just a few bytes can take up several kilobytes on traditional systems – effectively creating a 1000-fold expansion of files. Modern products utilize newer key-value stores to efficiently store variable amounts of metadata instead of using fixed blocks.
What Happens to Lawbreakers?
Not following the immutable laws of data reduction always results in penalties. Less available storage capacity. Greater disk expense due to more disks and support contract costs. There are also related data center footprint and power costs. The worst part is that penalties are often being paid and we don’t realize it—until we compare against a modern multi-layered approach to data reduction. We tend to think that all data reduction approaches are the same—and this simply isn’t the case.
Cohesity SmartFiles was designed to abide by the four immutable data reduction laws, and beyond, to deliver optimal efficiency. It provides advanced data deduplication, the ability to dedupe data across data center volumes, advanced data compression, and the elimination of small file storage amplification penalties. Learn more on the SmartFiles web page, blog, or read an ESG analyst report on SmartFiles data reduction.












