




Lately, I’ve been interfacing with a lot of enterprise customers looking for practical ways to overcome challenges with data protection and recovery strategies for their large, and growing, Oracle database infrastructures.
At issue: Oracle application owners and database admins face tough challenges when it comes to protecting a large number of databases. Data volumes are continuously expanding due to growth in database sizes, as well as regulatory compliance policies requiring increasingly extended data-retention periods.
 For the most part, these environments can’t even run protection jobs for specific Oracle databases because of their size and the time that it takes for a protection job to complete.
For the most part, these environments can’t even run protection jobs for specific Oracle databases because of their size and the time that it takes for a protection job to complete.
As a result, organizations end up considering expensive, complicated, and risky availability solutions. The hope is to find some form of data recoverability in the event of failure or corruption.
The scenario I just laid out is a recognized challenge in the data center, and one that enterprise organizations desperately need to overcome. When it comes to relational database management systems – and I have said this before – Oracle is one of the undeniable leaders in the business, and it’s also one of the most relied upon systems in the enterprise.
Database Trouble Makers
As mentioned above, new challenges have arisen from exponential data growth and the regulatory-compliance requirement to extend data retention periods. Oracle database environments just keep expanding.
Some technologies can help enterprises overcome these challenges. However, a suitable outcome isn’t always achieved. The implementation and support of space-efficiency features – such as compression and deduplication – are critical to success.
Following are some terms that are good to know for this discussion:
- Compression – Compression offers excellent value from a space-efficient and size-reduction perspective. However, its effectiveness and compression ratios are limited to the type of data to which these functions are being applied. The compression of data can be performed inline, or as a post process, depending on the capabilities of its implementation.
Note: There are pros and cons for the use of compression with Oracle databases, but we will hold that discussion for another day.
- Deduplication – There are two main ways in which deduplication can be performed: source-side and target-based deduplication. Also, deduplication techniques can be applied in one of two ways – used on a specific fault domain (single appliance) or globally.
* Target deduplication – Data is transmitted over a network onto a storage appliance (hardware or software), and then data is deduplicated at that point. The target-appliance approach is often more expensive, but it does provide some performance advantage when dealing with large amounts of data at scale.
* Source-side deduplication – Eliminates redundant data before transferring to a backup target repository at a server level. Source-side deduplication is implemented as a software component that runs on the server side where data is being protected. This server typically communicates with the data protection solution, which makes it possible for data to be deduplicated at its current location.
With source-side deduplication, data that has been partially transferred, or entirely transferred, is never transferred over the network again. This option reduces the utilization of network bandwidth. This is extremely valuable with respect to relational database management system and databases (Oracle).
For example, when using a file system to store database files, and a database is updated with new 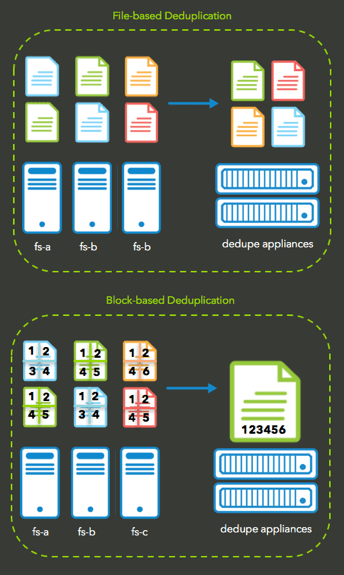 entries, that database file changes. With a traditional data protection product, that file will be transferred in its entirety … regardless of whether or not the protection job has been designated as an incremental protection job.
entries, that database file changes. With a traditional data protection product, that file will be transferred in its entirety … regardless of whether or not the protection job has been designated as an incremental protection job.
However, with source-side deduplication, a system can inspect files and identify the changes in bytes. Then it only transfers those changes over the network. This makes the transmission of data over a network more efficient.
File- vs Block-based
Data deduplication is performed at two different levels: file-based or block-based. Comparatively, file-based is the less efficient form of deduplication due to how it purges duplicated files.
- File-based deduplication focuses on performing comparisons on files (data) that are scheduled to be protected or archived against additional replicas of a file that has already been stored.
- Block-based deduplication is designed to look within files (data) to identify unique values within each block of data. Blocks are divided into multiple chunks of similar, fixed length, and their data is processed using either an MD5 or SHA-1 hash algorithm.
During this process, a unique identifier is generated for each chunk, and is then stored in an index. At this point, when a file is updated, only the changes are saved, regardless of the size of the change. Block-based deduplication is more efficient, but it comes at the cost of higher overhead in processing power.
How Cohesity’s DataPlatform Helps
Now why all of this rambling? Well, because it’s important to understand how Cohesity’s DataPlatform can help enterprise organizations overcome the challenges of data protection and recovery strategies for their Oracle database infrastructures. (Also, because Cohesity covers all of the technological points I made above, but with a much better and elegant implementation.)
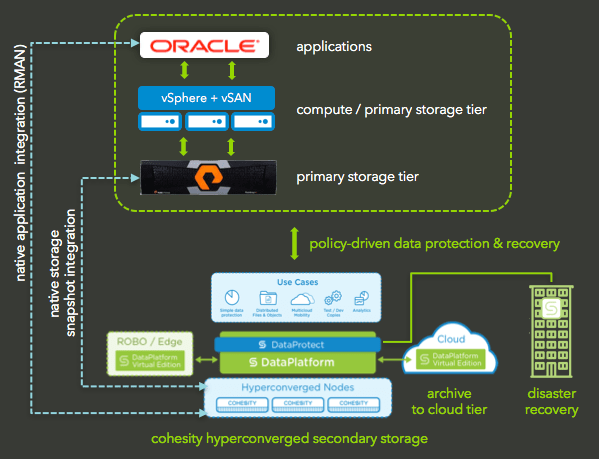
Cohesity’s hyperconverged data platform includes a converged data protection solution amongst all of its enterprise storage features and capabilities. It also consists of a converged data protection solution that provides end-to-end data protection capable of replacing traditional backup and recovery solutions and simplifying operations.
Together, Cohesity’s DataPlatform and DataProtect provide four different integration capabilities for Oracle databases.
Tight integration with Oracle RMAN APIs allows enterprises to perform application-consistent backups and restores, as well as risk-averse workflows for safe and efficient operating procedures.
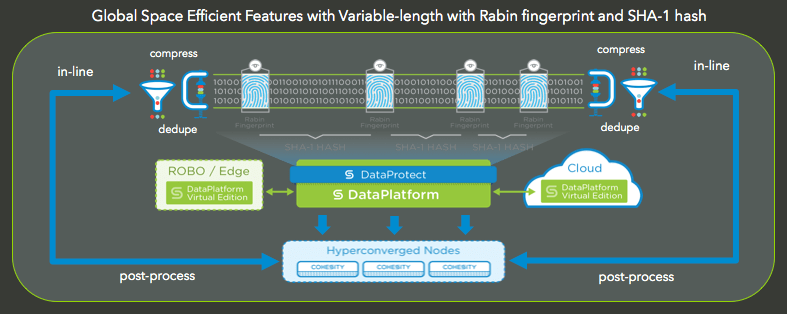
From a space-efficiency perspective, Cohesity’s DataPlatform provides global space efficiency features from global variable-length dedupe. This supports both in-line and post-process dedupe and compression.
COHESITY OFFERS FOUR POWERFUL ORACLE INTEGRATIONS THAT ARE CAPABLE OF MEETING THE DATA PROTECTION AND RECOVERY REQUIREMENTS OF THE MOST DEMANDING ENTERPRISE ORACLE DATABASE ENVIRONMENTS
DIRECT MOUNT OF COHESITY DATAPLATFORM TO ORACLE APPLICATION SERVERS
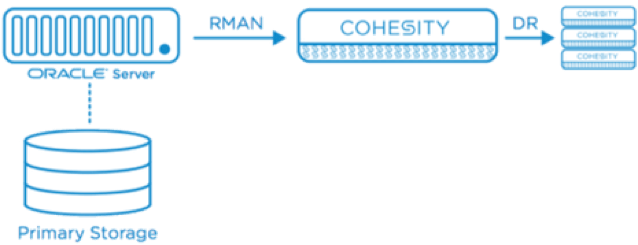
Cohesity storage abstractions can be presented as NFS volumes, enabling direct mounting to Oracle database servers. No intermediate media servers are required. RMAN automatically leverages Cohesity’s QoS policy for optimal data tiering, as well as global deduplication and compression, in order to reduce secondary storage consumption and footprint.
Benefits Of Automated Integration With Oracle RMAN:
- Automated and configurable Oracle RMAN based protection jobs.
- Significantly reduced recovery time; occurs by leveraging Oracle RMAN image-copy backups and ensuring that backup data is fully hydrated.
- Immutable backup ensures backups are not vulnerable to ransomware.
- Policy-based backups for Oracle databases; enables centralized scheduling of all RMAN scripts instead of manually scheduling backups across multiple Oracle servers.
- Simplified administration due to single-pane-of-glass for managing backup attributes and reports including:
- Tracking all backup tasks, schedules, and alerts from one place.
- Reporting on all backup tasks.
- Ability to clone Oracle Database from backup copies.
- Ability to have DBA registers as custom RMAN scripts for data protection.
SOURCE-SIDE DEDUPLICATION
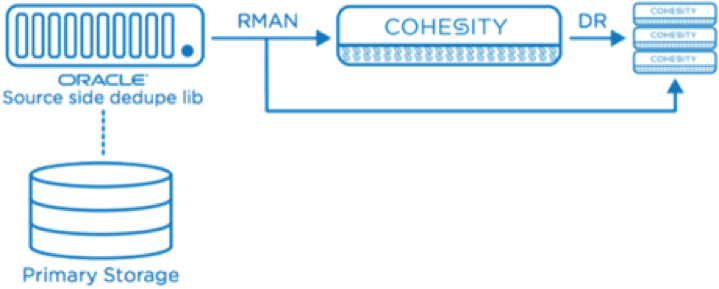
Cohesity source-side dedupe functionality for Oracle database servers provides backup admins with the following advantages:
- Faster backups to fit the ever-shrinking backup window.
- More frequent backups that result in lower RPOs.
- Reduces network traffic between host servers and backup target.
- Less load on the backup target in order to handle parallel ingest streams.
- Simple to use and deploy with existing Oracle instances.
- Eliminates need for asynchronous replication; ability to write Oracle Backup sets simultaneously to more than one Cohesity Appliance.
- Supports 11g & 12c versions of Oracle DB deployed on Oracle Enterprise Linux and Redhat Linux.
- Supports RMAN backups; configurations are full backups or incremental backups whether or not Oracle change block tracking is turned on.
SNAPSHOT OFFLOAD OF PRIMARY STORAGE ARRAYS
Through integration with primary storage arrays, Cohesity can easily and quickly offload and restore array data & snapshots, from and to production environments.
Here are some benefits:
- Optimal snapshot movement using primary storage array snapshot API.
- No disruption to database servers; all backups are taken directly from primary storage
- Faster backup and improved RTO & RPO over conventional app server backups.
- Provide application-consistent backups.
- Reduce storage requirements and overhead on production storage by moving older snapshots to secondary storage.
We’ve Got Your Back
From simplicity of management to risk-averse operational workflows to faster data protection and recovery, we’ve got you covered. Cohesity DataPlatform, DataProtect, and our integration with Oracle RMAN address a majority of challenges enterprises face today when it comes to data protection and recovery strategies of their large and growing Oracle database infrastructures.
To finish up, here is a demonstration showcasing one of Cohesity’s integration points with Oracle RMAN and the source-side deduplication configuration with multiple streams.
– Enjoy and don’t forget “The Sky’s the limit.”
For future updates about Cohesity, Hyperconverged Secondary Storage, and anything in our wonderful world of technology be sure to follow me on Twitter: @PunchingClouds.











