




Why do customers use the Cohesity Data Cloud? It’s the last line of defense to protect, detect, and recover valuable data from ransomware attacks—quickly and safely. Our technology minimizes the attack surface and makes us better at meeting more stringent backup SLAs, dramatically speeding all manner of recovery operations. We’ve built on that foundation to help customers recognize an attack sooner and react faster. We provide advanced threat detection signals with fewer false positives, fast and efficient ways to receive, manage, and act efficiently on alerts both to stop the attack and to accelerate the cleanup.
Keeping the Bad Guys at Bay
A distinct benefit of our backup process is intelligence gathering about the data and how it has changed. Anomalous changes in backup data can provide accurate early warnings without generating a lot of false alarms. For example, when new data is suddenly less compressible than past work, that’s a potential hallmark of having been encrypted. This is sometimes known as entropy detection because encrypted data looks very random, which is why it doesn’t compress.
To detect ongoing attacks and avoid false positives, Cohesity feeds multiple metrics into machine learning algorithms running in our Helios control plane, including but not limited to:
- Content information per backup: Size of data written, size of data read, logical size
- Entropy/compression ratio per backup
- Change tracking information per backup: Number of files added, files deleted, files updated, files unchanged
- Aggregated stats across multiple backups: Max data written bytes, max source logical size bytes, number of successful runs, and so on
- Training sets representing patterns of changes generated by commonly used malware
The machine learning models are not AI-washing of things that could just as easily be done traditionally; they are all multivariate models. Machine learning requires a baseline defining normal behavior, and Cohesity requires a minimum of 15 valid historical records to trigger a detection. With a baseline of metrics established, our models start with an aggressive learning phase and transition to a steady-state that is continually optimized for precision and recall.
We also have certain heuristic rule-based models written by humans to remove false positives. For example, if the data is compressible and the replacement files are equally compressible, it’s unlikely that there’s been a crypto attack. By combining multiple models, both human intelligence and raw machine learning are combined for optimal results.
In the spirit of continuous improvement, we also test additional machine learning models and compare the results. If improvements result from the latest damage patterns from the field, we can then upgrade the detection without gaps in the detection coverage.
Cohesity Ransomware Attack Detection
The most damaging malware attacks are hacker-driven, rather than spontaneous infections by malware in the wild that might infect your laptop or server. But virus damage is still possible. Such generic malware makes no attempt to be slow and sneaky, so their impacts are obvious. As you’d expect, we achieved 100% detection on samples of the damage patterns created by Cerber, Cryptxxx, Cryptolocker, Locky, and Wannacry run in a cloud account separate from any other Cohesity environment.
Because our ransomware attack detection capabilities are included in the platform for no additional cost to our customers and Software as a Service (SaaS)-based, we’ve accumulated extensive data to help train our models. This helps us adjust to the impacts of real-world attacks unleashed by hackers who have penetrated customer systems and used Cohesity backups to recover.
Because our ransomware attack detection is integrated with our backups, we can provide greater efficiency, improved detection, faster reaction times, and reduced risk to vaulted data. The encryption process used to ransom the data has the side effect of making the data look essentially random, or to use a fancy term, having high entropy. That “entropy” causes data reduction to become ineffective. Backup products perform data reduction, so they can notice the increased entropy without doing significant additional work. Having a standalone product separately read all the data to check entropy is wasteful. For that reason, when other backup vendors offer or suggest separate products for attack monitoring, those products either don’t check entropy, which degrades detection, or require costly additional resources to check entropy.
To partially work around the resource issue with entropy detection, standalone detection products may be run only after the backup has been completed and transferred to a separate cyber vault. That can further delay alerting if the vault is disconnected periodically for a time-based air gap. Updating the detection tools in the vault increases risk of accidentally contaminating the vault, such as with a compromised USB disk. Updates may be made less often in a vault, slowing adoption of training or algorithmic changes.
It’s natural and healthy for vendors to try to differentiate on detection capabilities. We’re sometimes asked if we check entropy (compressibility) on a file-by-file basis. To our knowledge, no vendor has ever done that as part of the analysis of determining whether to flag a backup as suspicious. The delay and resource penalty would outweigh any benefits. We have seen claims of a post-process step that conducts a file-level entropy analysis after a backup is deemed suspicious. This involves additional processing in the cluster not synergistic with the backup data flow, and can delay alerting. Our engineers have felt that doing so would not bring net value. Recently, competing claims of such per-file processing became part of explanations that were deemed “not to be relied upon” anymore while the replacement explanation of how things work conspicuously made no mention of checking entropy on a file-by-file basis.
The Need for Rapid, Confident, Coordinated Response
While we are confident in the value we provide by taking a data-centric view of attacks in progress, we know that in the real world correlation with other signals can further improve attack response agility. To enable fast response to incidents, SecOps personnel need to receive the alerts and have confidence in them to investigate it further. Cohesity can send the alerts directly to security orchestration and automation response (SOAR) platforms. A small but non-zero level of false positives is preferable to the extreme caution that would sometimes err on the side of non-detection. To keep good hygiene in cleaning up past alerts, we provide closed-loop integration with Palo Alto XSOAR and Cisco SecureX, allowing complete disposition from inside the SOAR platform. By leveraging automated playbooks, users need not log back into the backup UI to complete the response and thus reducing Mean time to detect (MTTD) and mean time to response (MTTR).
Here are some examples:
Cisco SecureX: To review and act upon an alert within Cisco SecureX with our integration, navigate to Incident and select the Incident for Cohesity Helios Anomalous object.
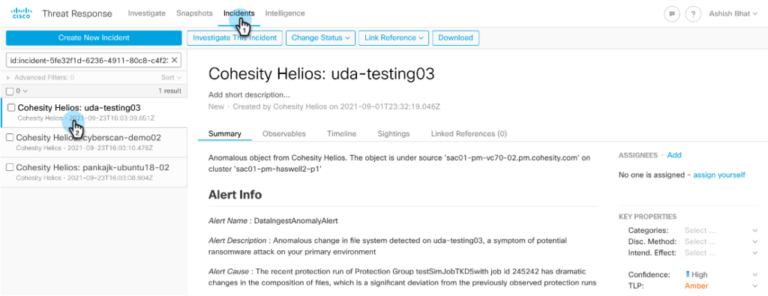
Under Observable, click the dropdown for the hostname and select Cohesity Restore Anomalous Object
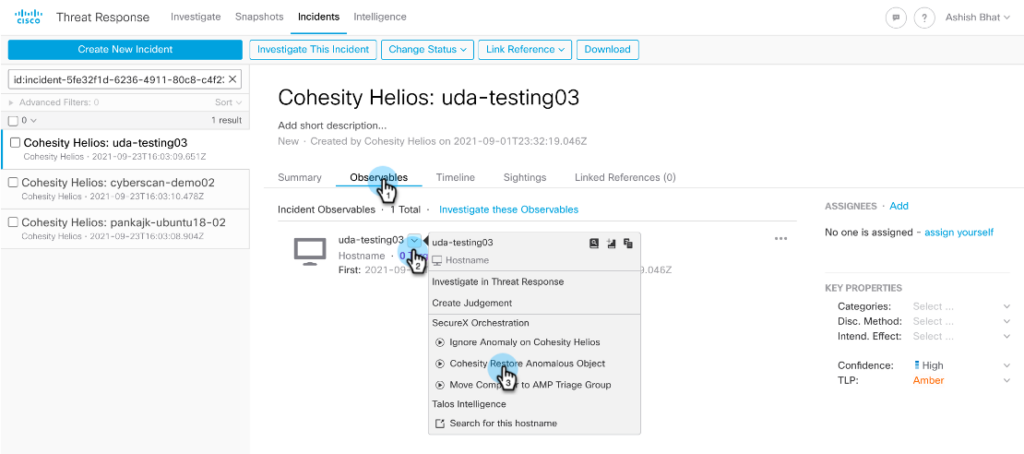
Palo Alto XSOAR: First research the anomaly within Ignore the Anomaly on XSOAR and then determine the action you need to take. In this case we have identified a false position and we are choosing “Ignore” to acknowledge this alert shown below
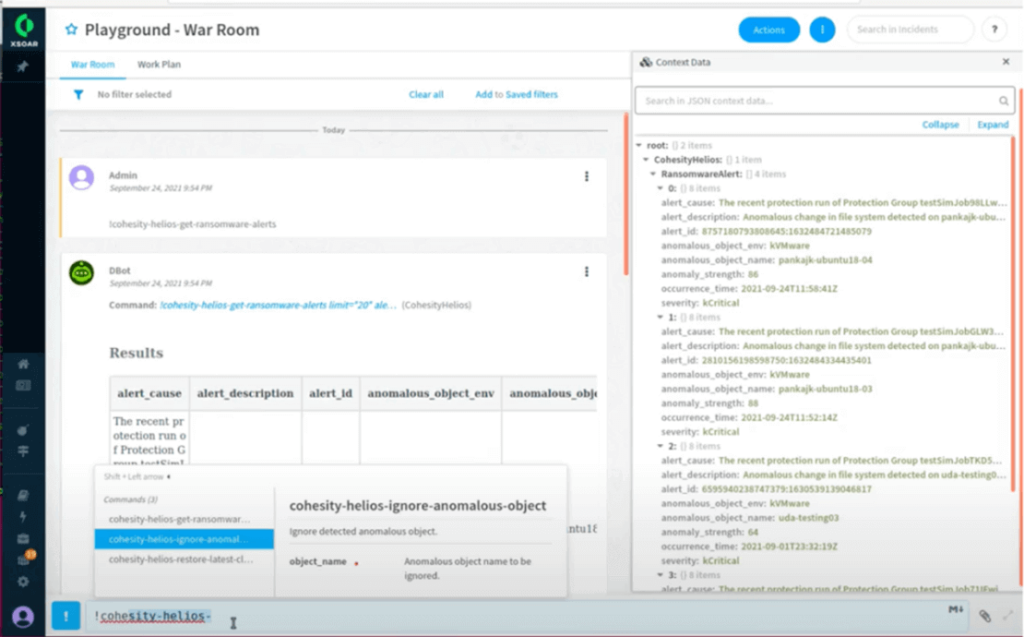
Having detected the attack, notified the admin via their phone, and integrated with incident response, the organization can work quickly to put a stop to any attack that comes their way.
Managing a Quick Recovery
With the attack stopped, can the detection output help our customers recover faster? Absolutely! Cohesity generates a list of the files that appear to have been attacked. And unlike other vendors who restore just the attacked files back into servers that were compromised, Cohesity customers whom we’ve helped recover from actual attacks unanimously tell a different story: Their security teams and their cyber insurance companies say restoring back into the compromised environments is unacceptable.
The real-world best-practice path is to restore all the data that has passed quarantine not into original servers or VMs but instead into clean-built servers or VMs, preferably ones that have been scanned for the latest known vulnerabilities and been found to be free of any high-risk problems.
When an actual attack has occurred, the many customers we’ve helped have all required quarantine processing in a sandbox for the whole dataset, not just the files that were overwritten. For examination of the whole dataset, Cohesity has uniquely scalable rapid mass restore and unique instant Network Attached Storage (NAS) access to NAS backups. These are driven by Cohesity’s unique snapshot metadata and robust file system technology, which remain under the covers.
This technology allows for quick recovery of organizational files and objects, allowing you to check for anomalies and work quickly toward a clean state of your data through what is known as Cohesity Smartfiles View or NAS.
How to Recover Your NAS to a Cohesity View Instantly
- Back up your NAS with Cohesity.
- Go to the Scope Selector within Cohesity and choose the cluster.
- Choose Recover > NAS > Storage Volume.
- Click your NAS to choose the correct back to recover from.
Instantly recover customer data to a new Cohesity view to get Instant NAS access
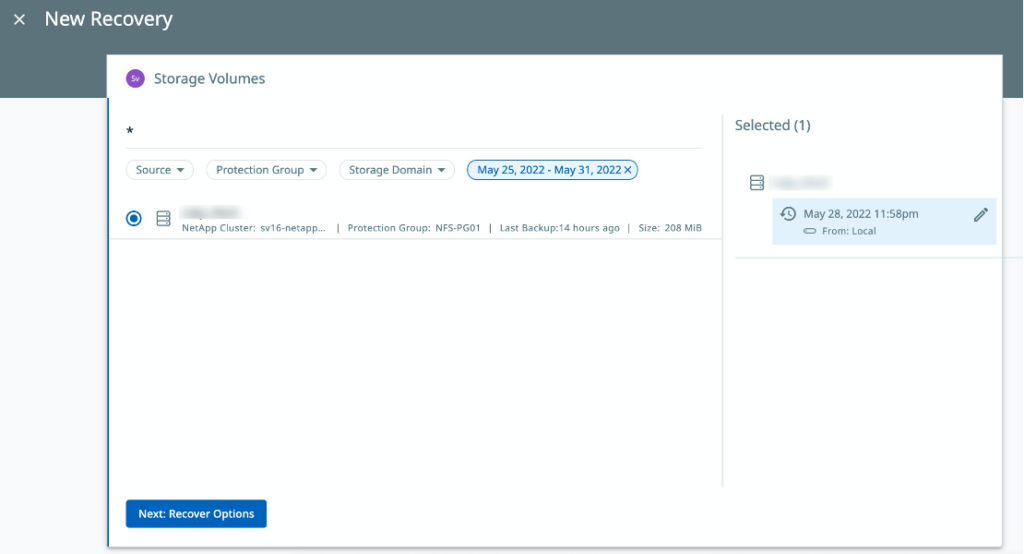
- Click the Next: Recover Options button.
- Select the settings shown in the image below to recover to a new Cohesity View and click Recover.
- Verify your recovery is completed and begin working with your files and objects data set within your Cohesity View.
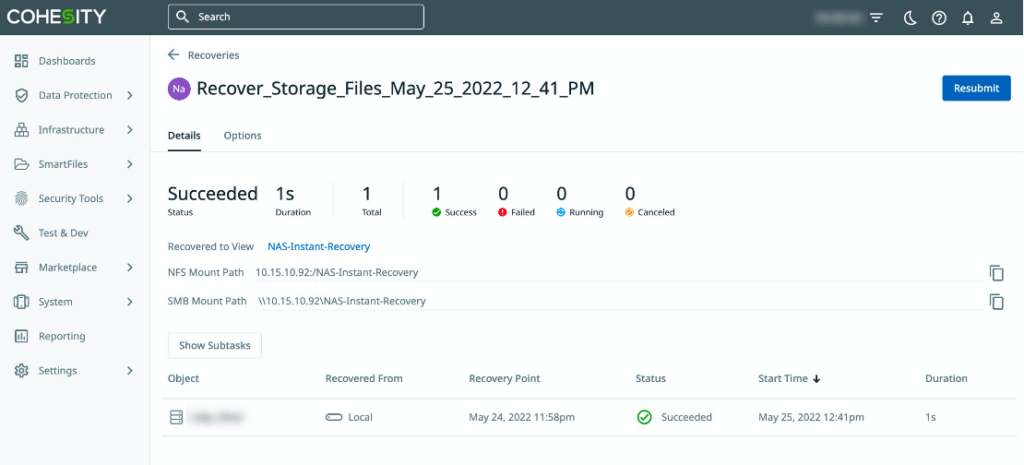
Instant NAS access is a critical technology for faster decontamination processes after an attack. It’s surprising then that some might call NAS access a liability. Let’s look deeper at how such arguments don’t connect with reality.
Immutable File Systems and NAS
An immutable file system provides a way to make snapshots of data, snapshots that not even the file system itself can modify once they are created. Our SmartFiles views into the file system have commands that any file server must have for adding or modifying or deleting files. Our backup software connects to our internal file system without using views. Once a snapshot has been created in our internal filesystem, either by our backup software or by Smartfiles, there are no commands, not even internally, for adding, modifying, or deleting files or for changing the content of the snapshot in any way.
Cohesity also provides for undeletability of the entire snapshot. In addition to the immutable snapshots, our DataLock capability provides an additional time-bound lock on the snapshot. This prevents the snapshots from being deleted even by super admin or even by Cohesity support until a specified number of days have passed.
During instant access, the immutable snapshots remain hidden. Zero-cost clones are exposed rather than the backups themselves. With our immutable snapshots, even if processes running on our nodes were to have a bug whereby it tries to change files, the result would be a new clone being created that has the new content rather than the backup data being modified—hence the term “immutable file system.”
Cohesity provides a deep converged solution, which reduces the attack surface. A vendor that has a NAS service and wants to get into the backup business might make a backup application that mounts a NAS view internally. That’s opposite to the Cohesity approach. Cohesity DataProtect predates SmartFiles. Cohesity DataProtect makes connections from the backed up servers to the cluster, and within the cluster between nodes, by using secure APIs and RPCs rather than open NAS or object protocols. The backup data cannot be enumerated or connected to other than via Cohesity APIs and RPCs.
There are cases where it’s desirable to have the native application dump data to a share that is subsequently immutably snapshotted and taken offline. To protect those workflows, Cohesity supports NFSv4.1 access control lists (ACLs) to prevent bad actors on the network from connecting to those temporary mounts to attempt to steal data.
Scalable and Reliable Live Access to Backups
When alerts indicate a problem with VMs, it’s important to accelerate the process sandbox operations. Eliminating the need to traverse chains makes our rapid mass restore more scalable. Use of deduped flash further accelerates instant mass restore.
Most backup systems are not intended to be used to serve up any data that may get updates needing protection against hardware hiccups. Cohesity’s file system is production-grade: No IO is considered complete until the new data is protected against node failure or reboot. With our true scale-out file system, node failure does not result in lost file handles and does not crash VMs or applications depending on that data being available.
How Cohesity Helps
Our foundation includes immutability that helps you protect your backup data. It also provides unique technology that enables organizations to accelerate cleanup and recovery/restoration back to normal operations at scale. Furthermore, Cohesity’s ransomware detection machine learning model addresses a key requirement in today’s cyber world, enabling customers to react faster and hasten their full recovery after an attack—particularly when integrated with leading third-party cybersecurity solutions. Together, our ability to protect your backup data, detect threats, and rapidly recover at scale serve to bolster your ability to minimize the impact of ransomware and other cyber threats.
Learn more:
Ransomware protection
Watch a demo video











