




Distributed Storage and Consistency Models
As monolithic systems reached their limits, they started getting replaced with scale-out distributed systems. The trend started two decades ago in compute when mainframes were replaced with server farms. Then made its way to storage (databases, file systems). In the database world, the Relational vs NoSQL debate has been raging for some time.
Today, I want to talk to you about distributed data storage platforms and consistency models. This is a very important requirement to consider when planning your storage infrastructure.
Let’s start with some basics. In a distributed system, the assumption is that individual nodes will fail. The system must be resilient to node failures. Therefore, the data must be duplicated across multiple nodes for redundancy.
In this context, let’s ask the following question: “If I perform a write (or update) on one node, will I always see the updated data across all the nodes?”
It seems like an innocuous question. Everyone would answer in the affirmative. “Duh, of course!”. But not so fast.
This is in fact a hard problem to solve in distributed systems, especially while maintaining performance. Systems that make this guarantee are called “strictly consistent”. However, a lot of systems take the easy way out, and only provide eventual consistency.
Eventual Consistency vs Strict Consistency
Let’s define eventual consistency vs strict consistency.
Eventual Consistency
The following video demonstrates the process of eventual consistency.
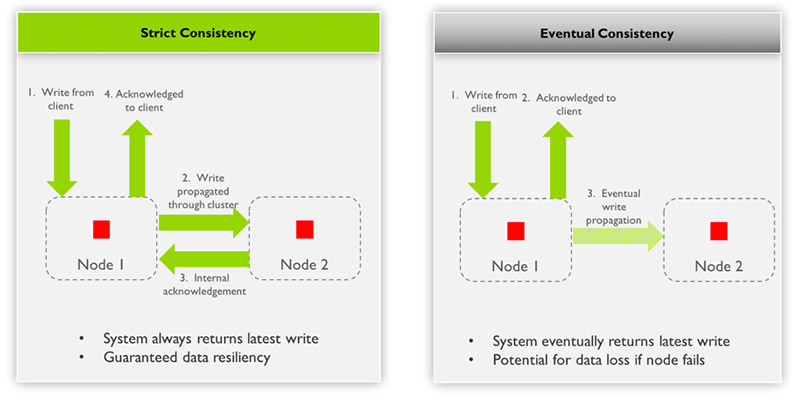
Summary of the process
- Write from client to node 1
- Acknowledge to client from node 1
- Eventual write propagates through cluster to node 2
Observations
- System eventually returns latest write: Weakens the conditions of consistency by adding the word “eventually”
- Potential for data loss if node fails: Adds the condition “provided there are no permanent failures.”
Strict Consistency
The following video demonstrates the process of strict consistency.
Summary of the process
- Write from client to node 1
- Write propagated through cluster, from node 1 to node 2
- Internal acknowledgement from node 2 to node 1
- Acknowledge to client from node 1
Observations
- System always returns the latest write: For any incoming write operation, once a write is acknowledged to the client the updated value is visible on read from any node.
- Guaranteed data resiliency: For any incoming write operation, once a write is acknowledged to the client the update is protected from node failure with redundancy.
Systems Do Not Always Use Strict Consistency
Clearly, strict consistency is better because the user is guaranteed to always see the latest data, and data is protected as soon as it is written. The illustration below compares the two consistency models.
Why Isn’t Strict Consistency Always Used?
Mostly because the implementation of strict consistency can significantly impact performance. Specifically, latency and throughput will be impacted. How much of an impact depends on the scenario.
Strict consistency isn’t always required and eventual consistency may suffice in some use cases. For example, in a shopping cart, say an item is added and the datacenter failed. It is not a disaster for the customer to add that item again. In this case eventual consistency would be sufficient.
However, you wouldn’t want this happening to your bank account with a deposit you just made. Having your money vanish because a node failed is unacceptable. Strict consistency is required in financial transactions.
Why Enterprise Storage Needs Strict Consistency
In enterprise storage, there are cases where eventual consistency is the right model, such as the example of cross-site replication. But in the vast majority of cases strict consistency is required. Let’s look at a few examples where strict consistency is needed.
Scale-Out File Storage
It so happens that one of the leading scale-out file storage systems provides only eventual consistency. The data is written to only one node (on NVRAM) and acknowledged. An enterprise customer once explained to me that under heavy load, a node may get marked offline. Effectively it’s down, resulting in clients getting “File-Not-Found” errors for files they had successfully written just a few seconds prior. This wreaks havoc on their applications.
Instant Recovery From Backup
Next-generation scale-out backup solutions provide instant VM recovery from backup. Such solutions boot VMs from a copy of the backup image on the backup system. The backup system serves as primary storage for the duration of the recovery, until the data can be moved back to the original datastore using Storage vMotion. The advantage is clear: you are back in business ASAP.
However, many scale-out backup solutions only provide eventual consistency for the writes. Consequently, if a failure happens on the recovery node, the application fails and the system loses live production VM data.
Data Protection
With strict consistency users are guaranteed to always see the latest data, and data is protected as soon as it is written. Thanks to strict consistency, application availability/uptime and no data loss are guaranteed, even if the infrastructure fails.
These considerations of scale-out file storage and instant recovery from backup should be top of mind as you design your backup environment.
Consistency Models in VM Environments
Infrastructures such as VMware vSphere and VMware Cloud Foundation require data resiliency and high availability. What does strict consistency and eventual consistency mean to such environments?
There are risks and problems that consistency models pose to any organization using traditional, or modern, data-protection and recovery solutions. Unfortunately, there is a tremendous lack of awareness and understanding about this topic.
Vendors offer traditional and modern methods for data protection and recovery solutions. They provide quick restore of a VM or data with a feature often called Instant Recovery. The goal is to minimize downtime, known as the Recovery Time Objective (RTO).
However, the restoration workflow and implementation is different depending on the vendor and customer’s infrastructure.
Data Protection
There are a series of recovery functions performed (manual or automatic) to restore an environment such as VMware vSphere. Typically, the data protection and recovery solution, where a copy of the VM or data is stored, provides some form of a storage abstraction. vSphere will provide the additional compute resources for this.
Data Recovery
After the VM is recovered, it has to be migrated back to the primary storage platform. In vSphere, Storage vMotion is used to migrate data over the network. It possible to recover and instantiate a VM in minutes.
Yet, it’s not possible to restore in a few minutes if it means moving hundreds of gigabytes across a network. Depending on the size and capacity being transferred across the network, the process can take a long time to complete. Low times will depend on network bandwidth, interface saturation, etc.
Data Protection and Recovery with Eventual Consistency
This video illustrates the process of restoring a vSphere environment with vMotion using eventual consistency.
Summary of the process
- Prepare and restore the VM locally onto a storage abstraction as an NFS volume. The abstraction is presented to vSphere from a single node based on the eventual consistency model.
- Mount the NFS storage abstraction from one of the nodes in the data protection and recovery cluster. VM is instantiated and accessible on vSphere. Read and write I/O are directed to the VM stored on the storage abstraction (NFS) presented from a single node.
- At this moment new data being created is not protected. It is not distributed across the other nodes in the data protection and recovery cluster.
- SvMotion starts the migration of the VM back to the primary storage platform.This can take a long time, depending on the environment.
- If a node in the data protection and recovery cluster fails while restoring to vSphere, the following happens:
-
- The storage abstraction (NFS) becomes inaccessible to vSphere
- The VM is no longer available or accessible
- SvMotion fails
- Any newly created data can be lost
This is not an acceptable outcome when you depend on a data protection and recovery solution as your insurance policy. The result – depending on the magnitude of the failure – can put a company out of business, or at the very least, cost someone their job.
Data Protection and Recovery with Strict Consistency
This video illustrates the process of restoring a vSphere environment with vMotion using strict consistency.
The steps below are what enterprises should expect. This is what they should demand from their data protection and recovery solution.
- Prepare and restore the VM locally onto a storage abstraction that is presented to vSphere in the form of an NFS volume. The abstraction is presented based on the strict consistency model.
- Automatically present and mount the storage abstraction to vSphere (NFS) from a virtual IP from the Cohesity cluster. The VM is instantiated and accessible on vSphere. Read and write I/O are directed to the VM stored on the storage abstraction (NFS) presented from the virtual IP of the Cohesity cluster.
- New data being created is distributed and acknowledged across the other nodes in the Cohesity cluster.
- SvMotion starts the migration of the VM back to the primary storage platform – this can take a long time.
- If a node in the Cohesity cluster fails, the storage abstraction (NFS) being presented to vSphere remains available. The SvMotion will continue until completed because of the use of virtual IPs and Strict Consistency, which together mitigate the risk of data loss.
The steps described above result in the outcome enterprises should expect, and demand, from their data protection and recovery solution when looking to leverage features such as Instant Recovery.
This video summarizes the information above, and demonstrates the issue strict vs eventual consistency. It takes you through two scenarios step by step. The first example is about backups with Oracle RMAN and the next is performing an instant restore for VMware.
How Cohesity Can Help
This article explained why Cohesity implements strict consistency. It mitigates the risks of data inaccessibility and potential data loss due to node failure. Before you choose your data protection and recovery solution, consider the questions about its underlying design principles.
With strict consistency, data written to Cohesity is acknowledged only after it is safely written to multiple nodes in the cluster – not just to one node. This avoids a single point of failure. And that’s critical to avoid downtime and maintain business continuity.
Cohesity’s DataPlatform features, capabilities, and modern architecture were designed to meet the requirements of businesses today – not two-to-three decades ago. Check out Cohesity SpanFS and learn more about how our file system provides you with the highest levels of performance, resilience, and scale.










