






Cohesity innovates fast. With fast innovation comes new releases packed with an ever growing list of new and updated features including dedup, compression, fully hydrated snapshots, software based encryption, mixed workloads, global search, analytics, and node by node cluster expansion.
All this new functionality is great, but our customers also tell us that they don’t want to deal with frequent disruptive upgrades. To provide access to all the latest and greatest features with minimum disruption, Cohesity has developed a smooth and painless upgrade workflow. This same upgrade workflow is used for software upgrades, security updates, firmware upgrades, and even OS upgrades. We keep it simple. One upgrade workflow for everything.
In this post, we’ll go over how Cohesity’s upgrade process works and why designing upgrade right is so important for any enterprise-grade system.
Active-Passive Root Partition Scheme
Linux users may be familiar with the common update workflows using yum or apt-get. Those package managers have been known to cause problems when they move configuration files around, force daemons to use new libraries, or leave the system in an inconsistent state when interrupted. Using these package managers for an enterprise quality system can result in an inconceivable number of permutations of libraries and executables (usually referred to as dependency hell). Recovering from such failure scenarios can be a puzzle. When Cohesity gets a support call, our goal is to address the issue in the earliest possible time. We achieve that by maintaining a consistent system image across all the appliances in the field.
Thankfully, the Cohesity upgrade avoids all those issues. Each node uses an active-passive root partition scheme to make our consistent upgrades possible. One active partition hosts the current OS, while another passive partition is reserved for upgrades. We deploy our upgrades to the passive partition and, in one atomic operation, set the passive partition to become active after a restart. And while the node restarts, there is no disruption to the cluster as we’ll discuss in the next section. The node’s entire OS is upgraded at the same time. That means a Cohesity node is never in a partially upgraded state. It also means that our upgrades are powerful enough to change nearly any part of the system, which makes our software more future proof.
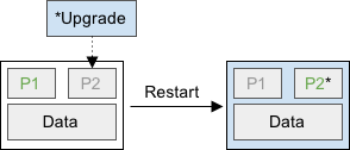
Partition P1 is active while the upgrade is deployed on passive partition P2.
After restart, partition P2 is active and running the new software, while partition P1 is passive.>
Non-disruptive Rolling Upgrades
For some other storage systems, you may discover that upgrades and other maintenance tasks require downtime. With different groups of users and applications using the storage system, it can be difficult if not impossible to negotiate a downtime window that satisfies all stakeholders. Furthermore, scheduling downtime can put the business’s RPO and RTO at risk, and in the case of critical security updates, delaying an upgrade to schedule a more agreeable downtime window may mean putting the data itself at risk.
A Cohesity cluster is a fault tolerant distributed system. When hardware fails and brings a node down, other nodes pick up the work and the system stays available and consistent. The same is true during upgrades — the system stays available and consistent throughout the entire process. No need to schedule downtime for the upgrade; no need to babysit the upgrade; no risk to RPO, RTO, or data security; completely hands off and pain free. This should be the expectation for any modern enterprise system and one that every customer should test when evaluating such systems.
Recently a potential customer was evaluating the Cohesity cluster by running backup jobs and using the GUI for monitoring and administration. When the customer kicked off an upgrade, their backup jobs kept running and the customer didn’t lose access to the dashboard. This ended up being a significant differentiator. A competing solution fell flat when their disruptive upgrade caused the customer to lose GUI access and stopped the running jobs. All the while, the upgrade was being run by remote tech support instead of self-driven by the customer.

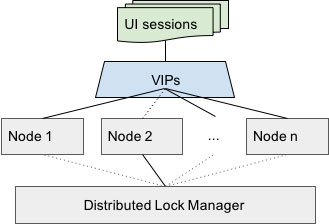
How does Cohesity do it? When a cluster upgrade is initiated, each node upgrades one after another until all are running the new software. This coordination is facilitated by our distributed lock manager. Nodes race to acquire a token, and only the winner proceeds to upgrade. After a node finishes, the process repeats.
When a node starts upgrading, its services are temporarily brought down. Meanwhile other nodes in the cluster automatically pick up its workload. This seamless work redistribution is made possible by our virtual IPs (VIPS) service. The upgrading node’s VIPs are migrated to other nodes in the cluster. Any requests to those VIPs will get served by the other nodes. That means you can continue using the same UI session from upgrade start to finish.
1-Click Upgrade
Okay, so the Cohesity upgrade is seamless, it’s non-disruptive, and it can even replace the underlying OS distribution. But is it easy? With traditional secondary storage systems you might have separate platforms for your data protection, file services, analytics, and test and dev. Each with different firmware and driver versions, different upgrade packages, different hardware-software compatibilities, and different version compatibilities between each other. Do you need to upgrade the firmware before upgrading the software? Which platform should be upgraded first to avoid breaking API compatibility with other running systems? The compatibility and dependency matrices can quickly grow unmanageable. Sometimes you may even need to call Professional Services for help. And while some companies publish complicated interoperability tools you can use to determine version and upgrade compatibilities, that still puts the burden on the user. Luckily with Cohesity you can forget all of that.

The Cohesity cluster stays synchronized with all the new Cohesity software release packages published by our public release service. The Cohesity release team manages the public release service to control the rollout of upgrade packages. There is no need to worry about whether an upgrade package is compatible with your current system. All of that logic is handled for you behind the scenes. The UI shows only the versions compatible with your cluster. Simply select your desired upgrade version, and in one click the cluster upgrade will kick off. This means that upgrades can be self-driven by customers without remote tech support and unnecessary hand holding.
Simple. One click. No downtime. Upgrade your experience.
Conclusion
Cohesity provides a one click, non-disruptive cluster upgrade that has the potential to handle any changes needed to improve our software. The whole process is fully automated. Your backup jobs keep running; your replication tasks continue transmitting; your files keep getting indexed. No I/O interruption, no maintenance modes, and no data relocation necessary. This is what makes Cohesity a true scale-out system.








